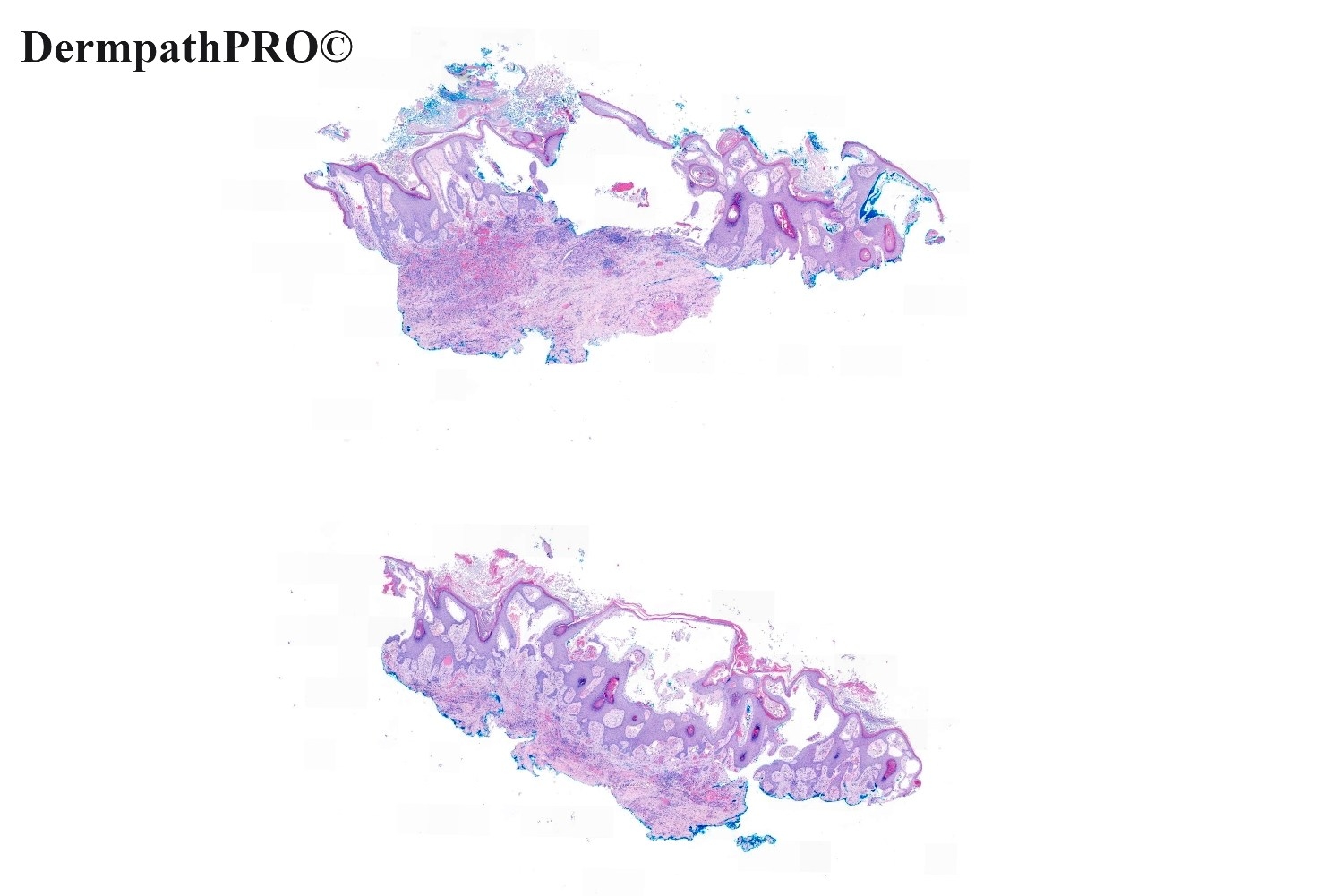
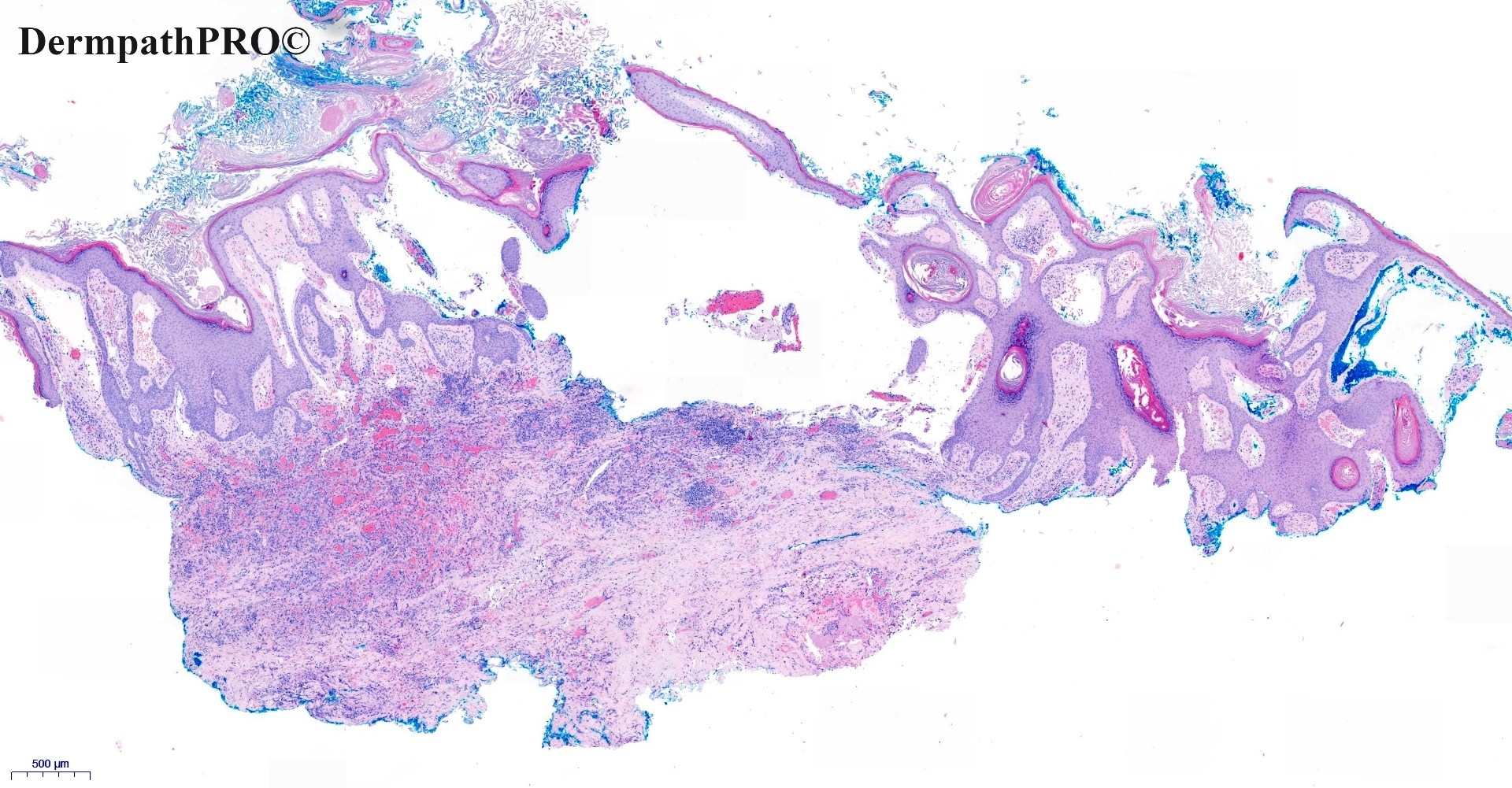
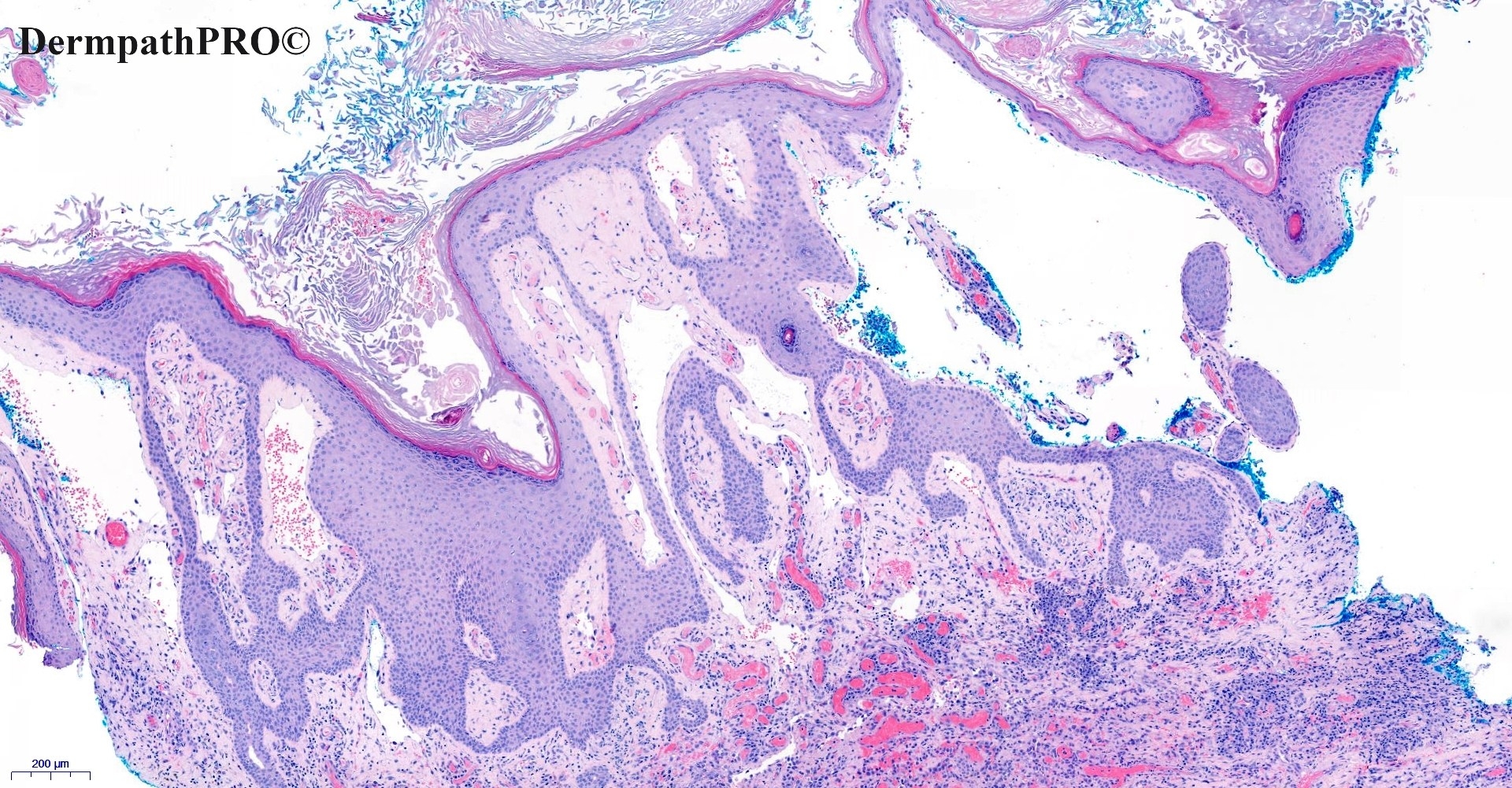
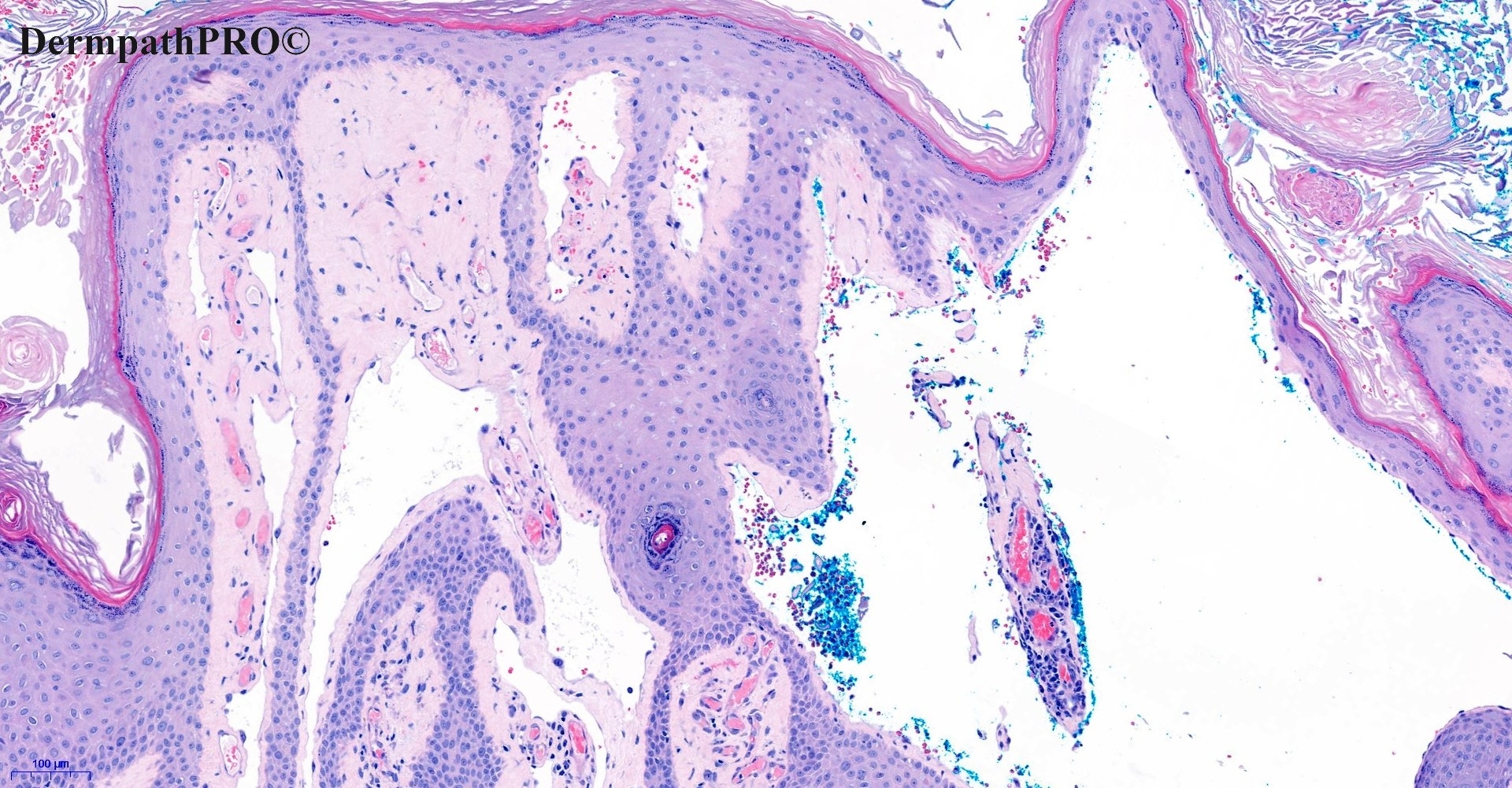
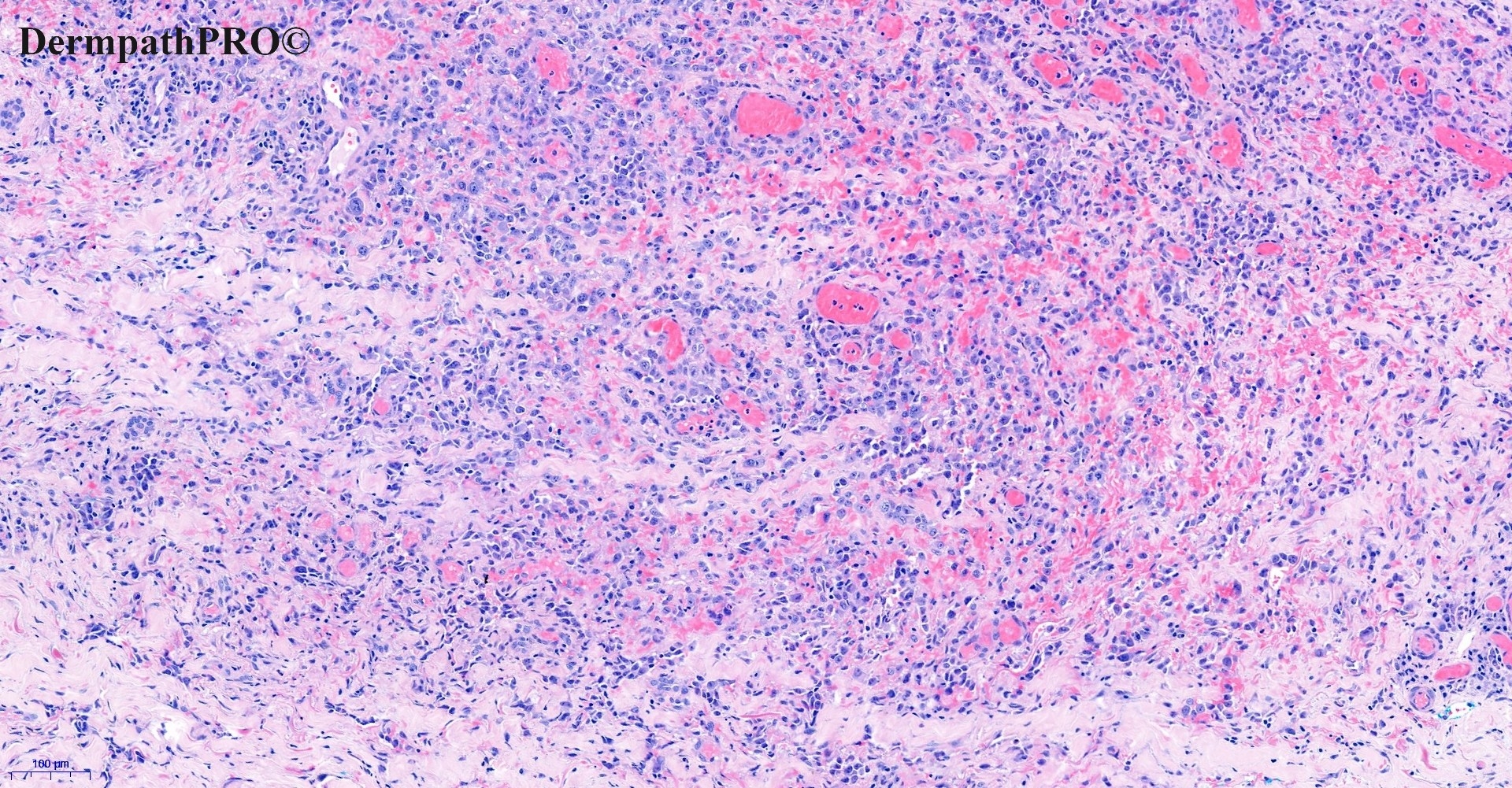
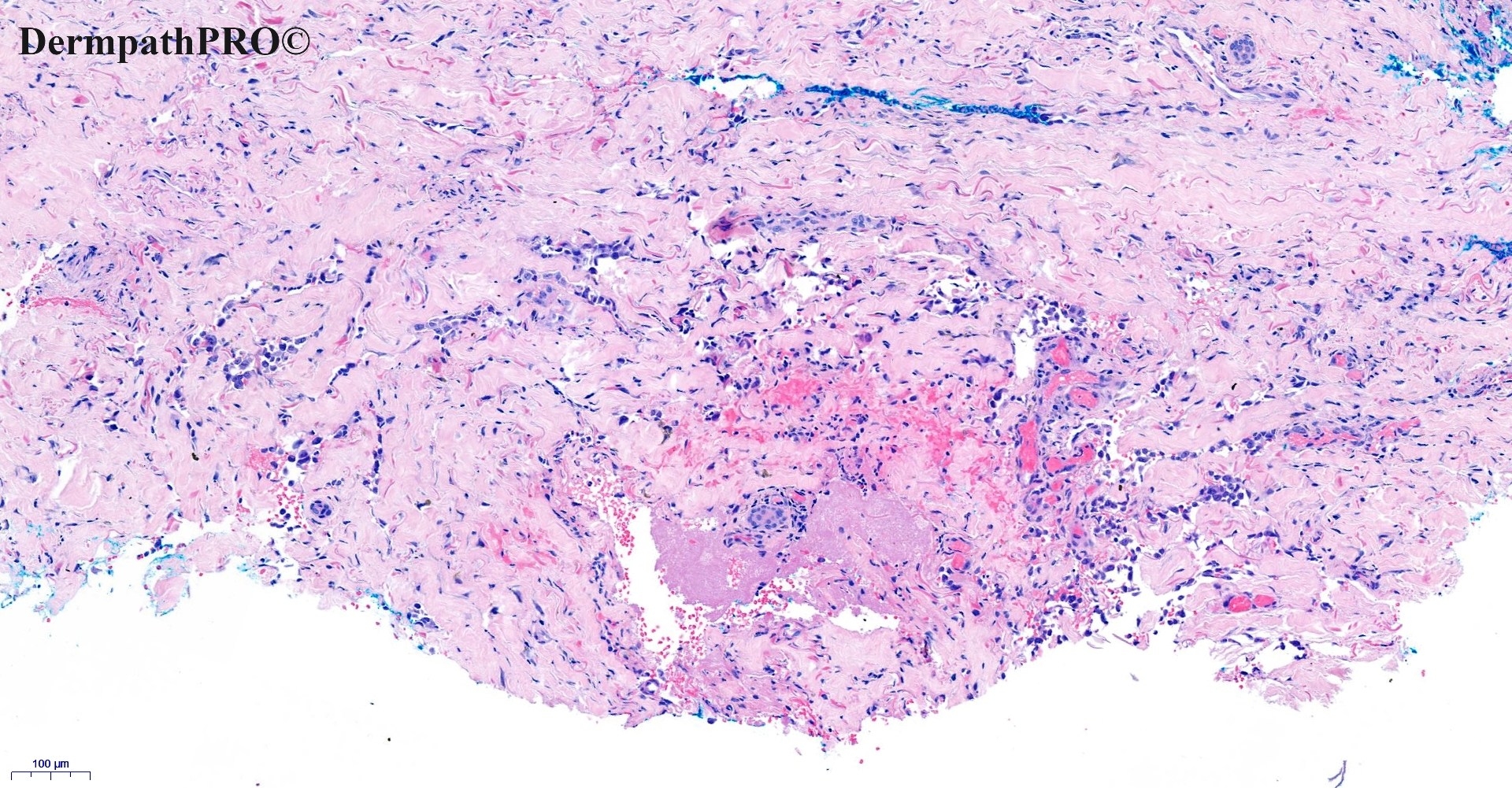
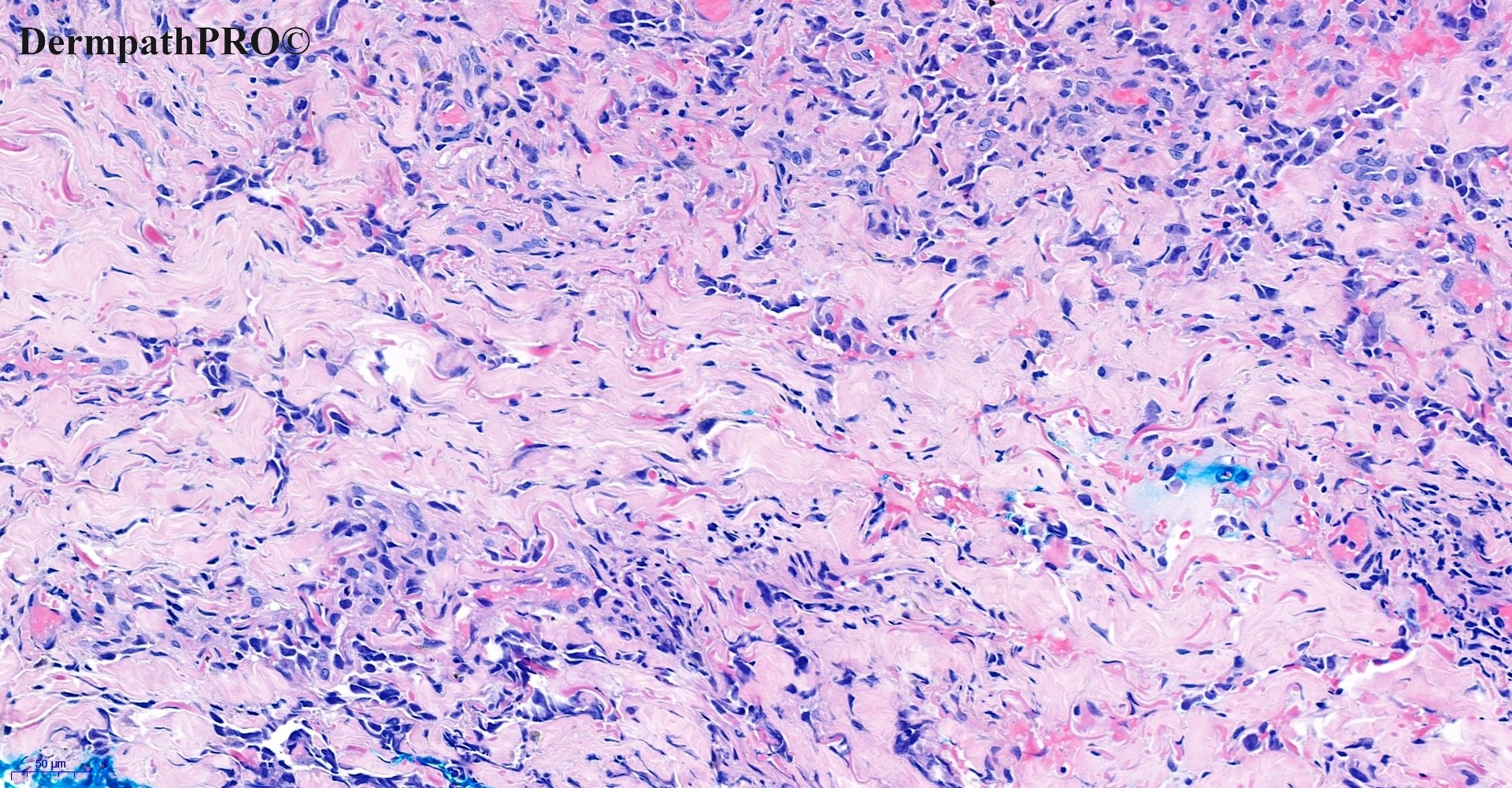
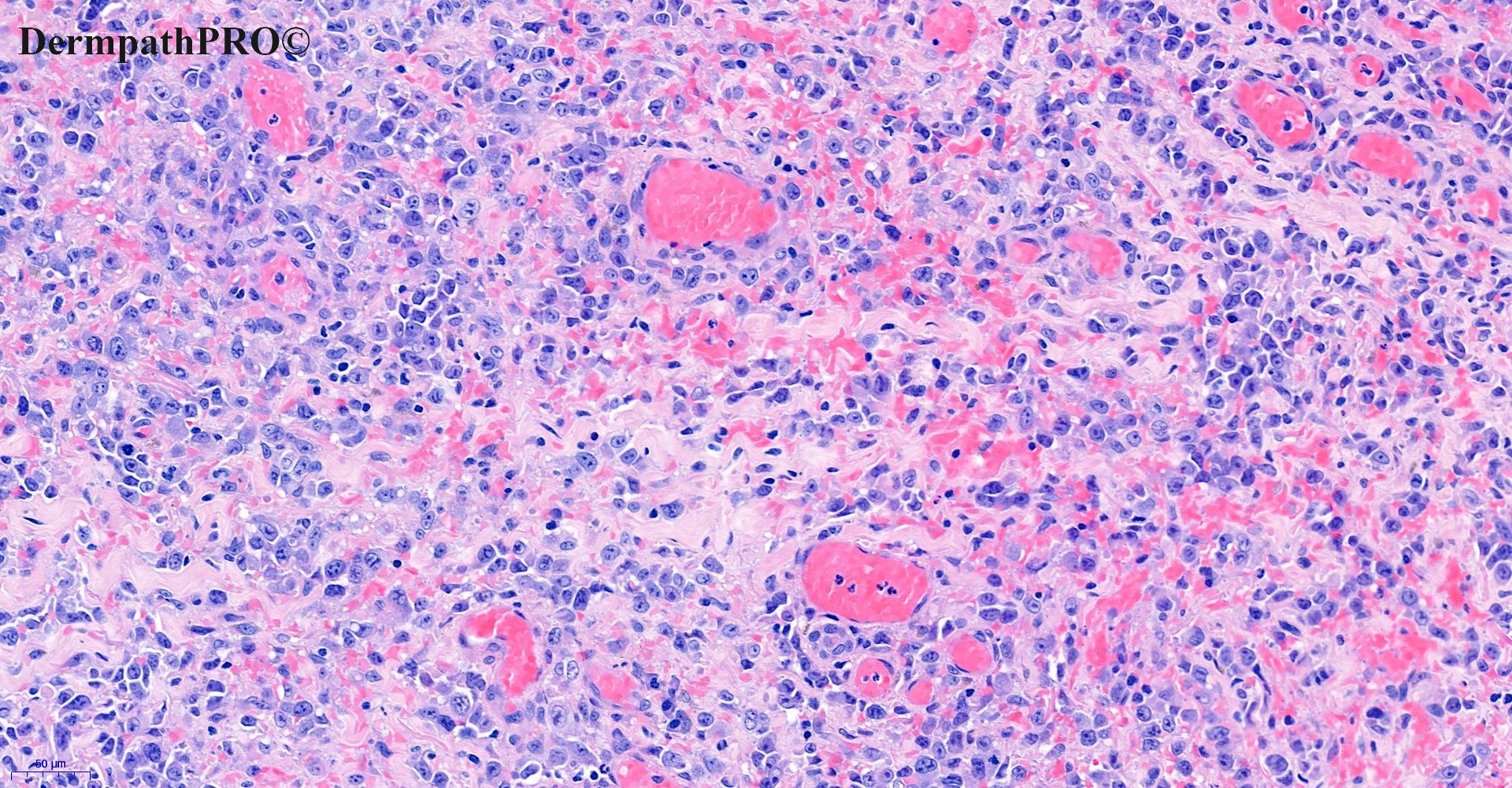
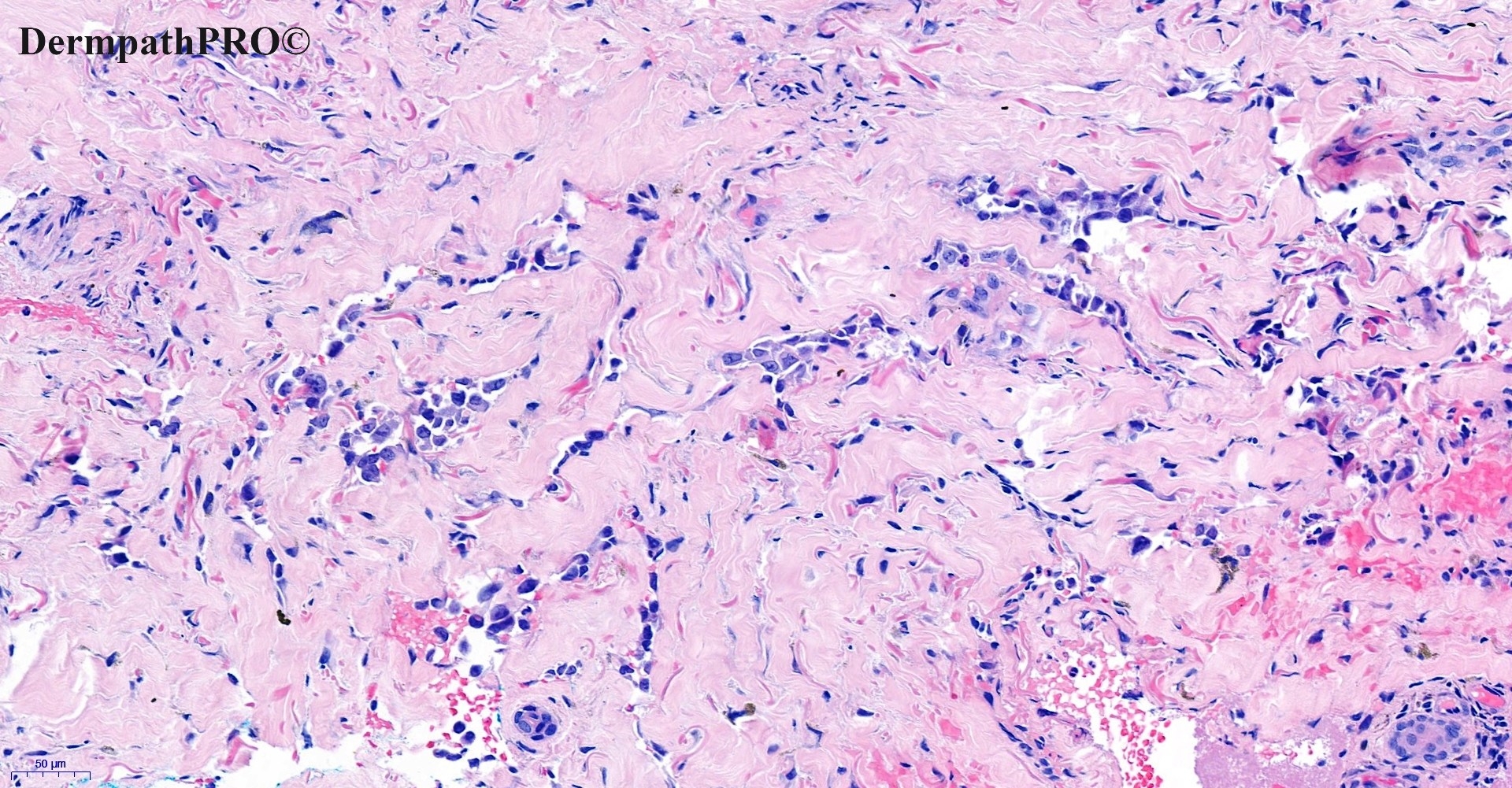
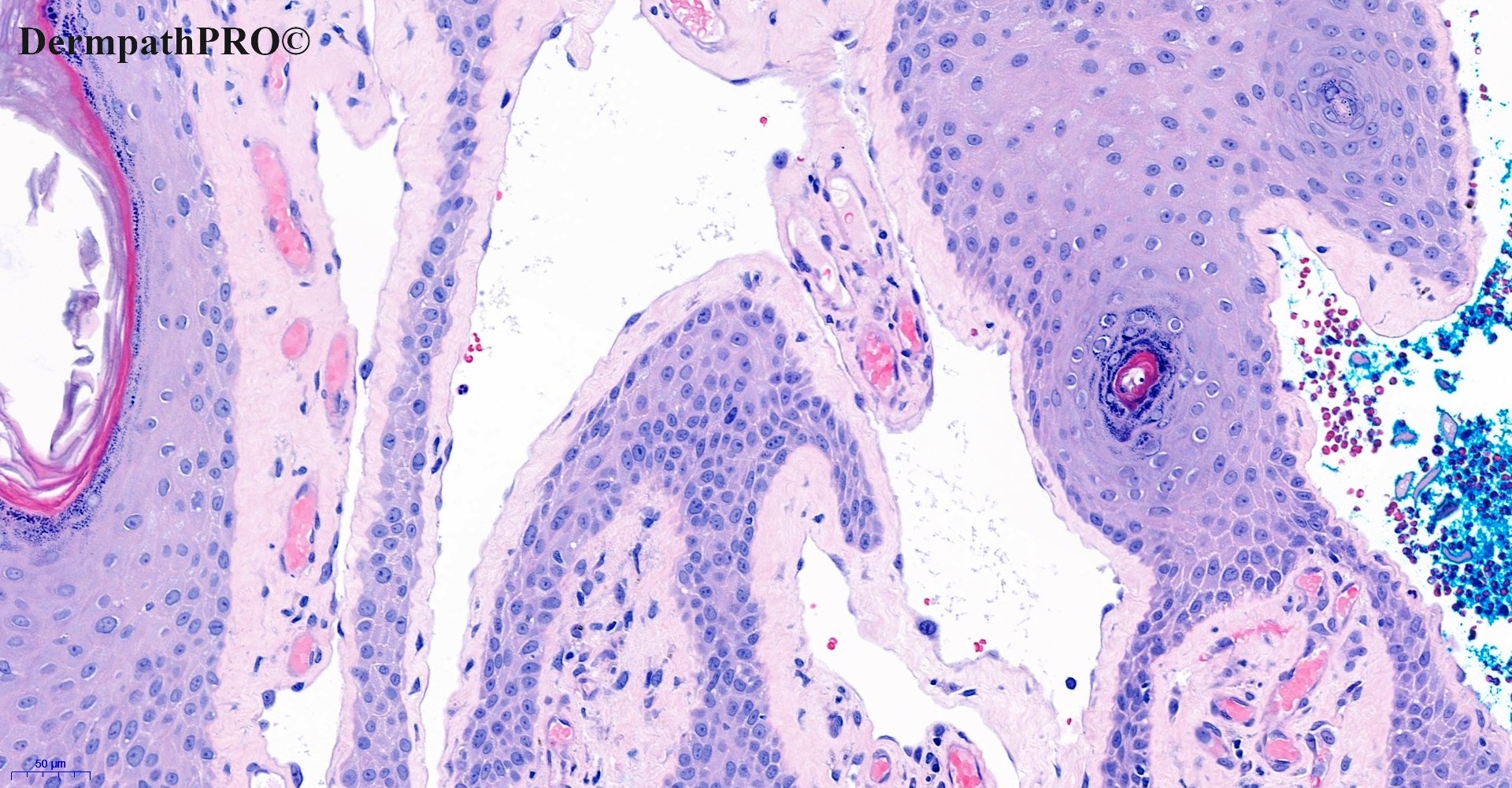
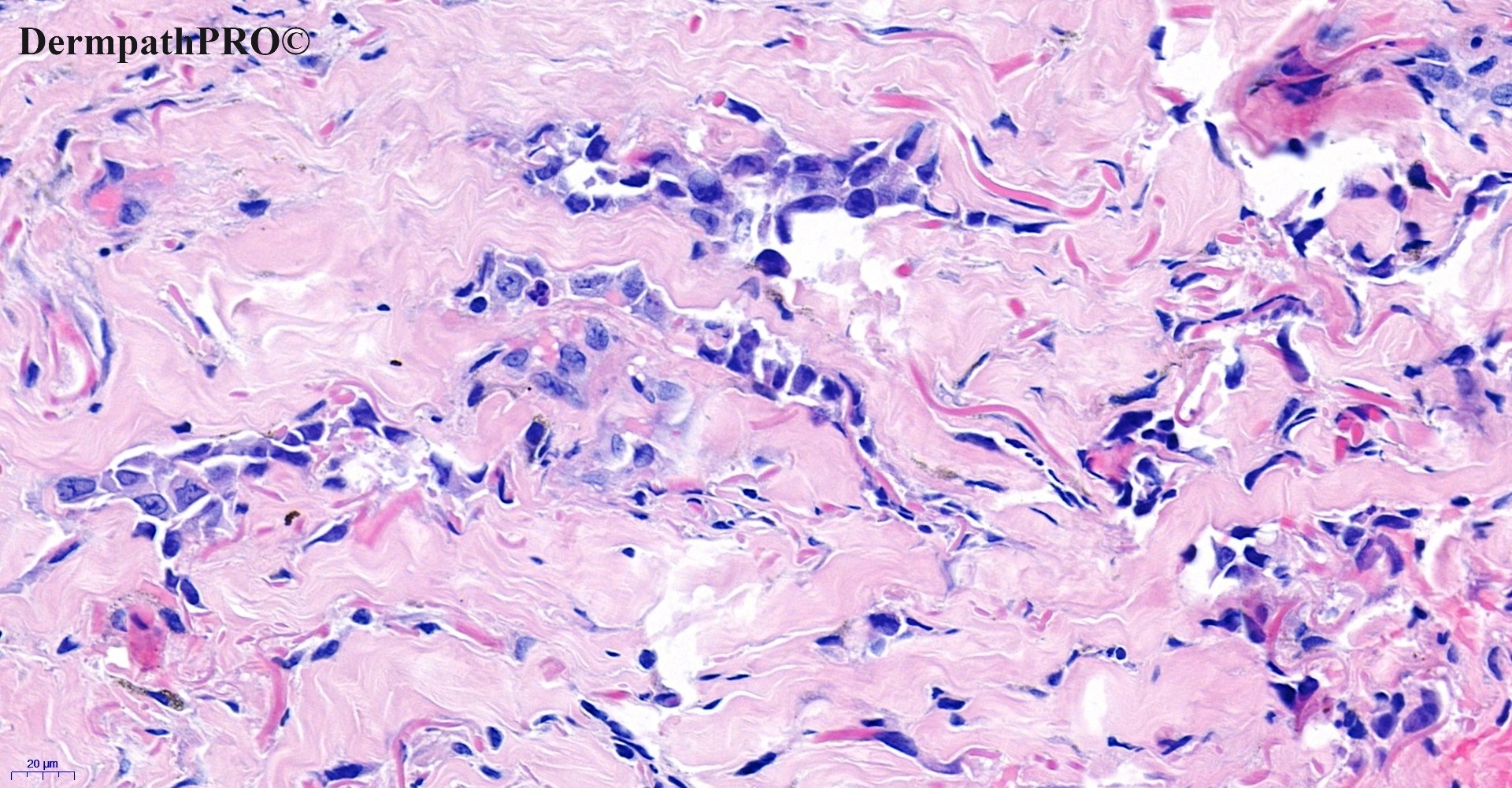
In this section we have spot diagnoses posted on a daily basis since June 2010, now over 4000! You can review the archived cases and read the suggested diagnoses by users and the final comment by the contributors. Case are uploaded each week day by 10 am UK time with the correct diagnosis will generally be posted at 8 pm UK time. Why not view the most recent spot diagnosis and proffer a diagnosis?
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.